Introduction — Background on this article…
For years after the .NET Framework became popular around 2002, I wondered how the String GetHashCode method behaved. How good was it? By good I mean does it produce a widely distributed set of output values that are collision resistant, which are highly desirable attributes of any Hash algorithm (as explained in Wikipedia).
For some reason back then I was especially curious about how
My initial experiments with
Around 2005 I wrote a Windows Forms program to calculate the hashes of random strings of various lengths and plot them in a grid. The technique I used to convert hash values into plot points is completely fabricated and has no solid mathematical theory behind it, but it usually reveals how distributed the values are in 32‑bit space and if they have any lattice structure.
The hash-to-plot technique involves splitting the 32‑bit hash into two 16-bit halves which are divided by 64 to produce a pair of numbers in the range 0-1023 which are used as the X-Y coordinates of the plot point.
If the hash algorithm produces an output larger than 32‑bits then various hacks are used to squeeze the value down to 32‑bits. I feel dreadfully guilty about using such questionable 32‑bit reduction hacks which can distort the plot results, but I'll let that go for now because this article is just for fun and not academic rigour.
In late 2022 I rewrote the original Windows Forms program to use the WPF platform, which resulted in a much more pleasant program with much less code. Following is a screenshot of the program. The source code is available in the Azure DevOps repository, and the Wiki page contains more information.
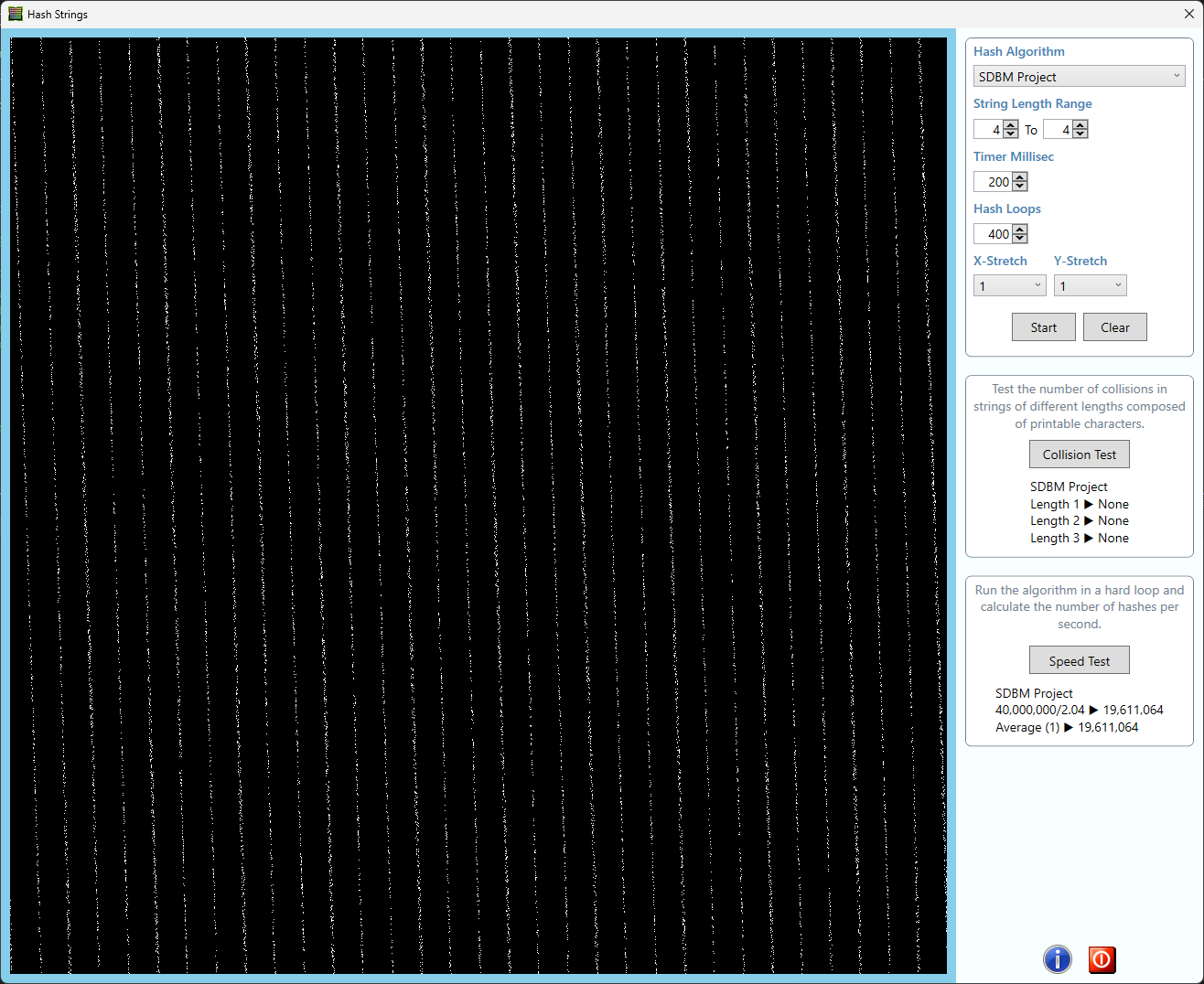
The drop-down list provides the following choices of hash algorithms to be plotted. To save space I won't bother describing all of these algorithms, as web searches will quickly provide many useful links. The footnotes clarify what's happening in some algorithms.
|
|
[1] The CRC64‑64 algorithm's hash was reduced to 32 bits by XOR "folding" the high 32 bits with the low 32 bits.
[2] The XxHash-64 collisions should be ignored, because XOR "folding" the 64 bits down to 32 ruins its carefully designed algorithm. The Xxhash authors claim it's one of the best contemporary hashers available.
[3] "Leading" means the first 4 bytes of the hash output buffer are used to generate an Int32 hash. "Folded" means that consecutive groups of 4 bytes are xor'd together to make the final hash.
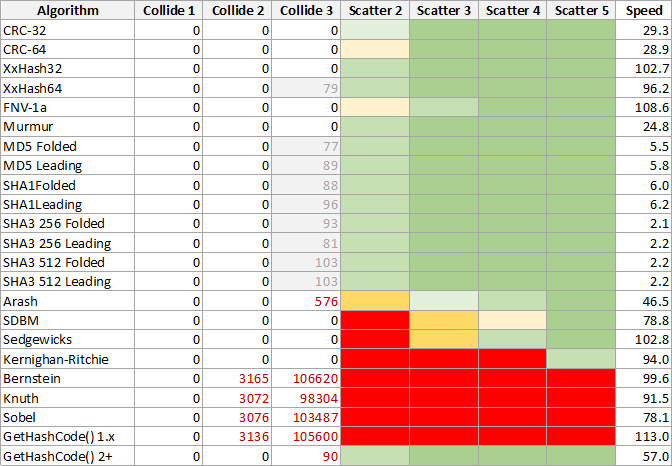
Collisions
The three Collide columns count how many collisions were found for all strings made from all combinations of one, two and three characters taken from a set of 96 printable ASCII characters in the range 32 to 127. Zero collision counts are highly desirable.
Note that the collisions in the XxHash64, MD5 and SHA algorithms are deceptions. They are all caused by folding the full hash down to 32‑bits. The grey cells should be ignored.
A separate test confirms that XxHash64 does not produce any 64‑bit collisions from 3-character inputs.
The MD5 and SHA algorithms are highly respected and trusted to produce widely-distributed values with an astronomically tiny chance of producing collisions. The fact that collisions were found by taking the leading 32‑bits of their hashes or folding them down to 32‑bits simply reveals some peculiar pattern in the way the bits are internally scrambled. A separate test confirms no collisions in the full hash values. The lesson here is that you should never take pieces of full cryptographic hash values.
Scatter/Distribution
The colours in the four Scatter titled result columns are a rough guide to how visually distributed (or scattered) the hash values are in 32‑bit space. Darkest green is the best ranging to pure red as the worst. The point coordinates in the plot areas are made from each hash value by taking X=(left 16 bits) and Y=(right 16 bits). This technique will often reveal correlations and biases in hash values, or will simply indicate that they fall into a relatively small range. In many algorithms the plot points are densely packed into small ranges, show lattice structures or unusual patterns.
It's important to note that poor distribution in the 32‑bit space does not imply the algorithm is weak or flawed. Some of the algorithms produce no collisions, but they have hash values for 2 to 4 character strings squashed into a narrow range.
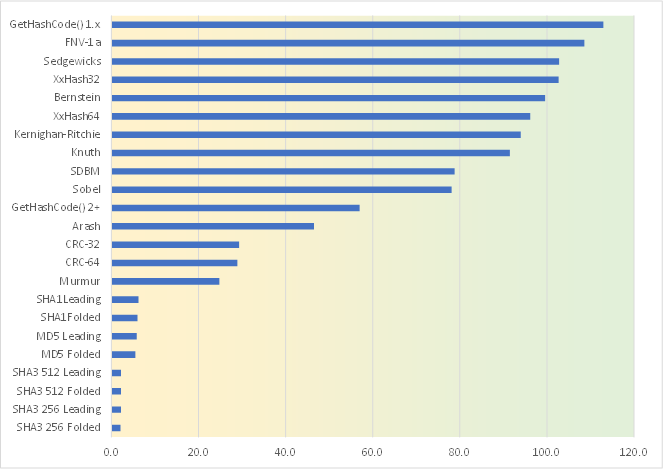
The speed test shows that the hash algorithms roughly fall into three groups. All of the simple algorithms that use tight loops with simple arithmetic and binary operations run at higher speeds. The CRCs run at about 40% speed. The crypto hashes all run at about 2% speed. See also: PRNG Relative Performance. The x-axis scale is millions per second.
Updated December 2022
Data Integrity
For data integrity checksums I use the 16 byte values produced by MD5. For example, a uniqueidentifier column can be added to an RDB table to hold row checksum values. The values are not visible to the public. MD5 is cryptographically weak and must not be used in public code or data, in that case you should use one of the modern SHA family of algorithms (and use them properly!).
64-Bit Hash
64‑bit hashes are efficient to calculate and store, and they are collision resistant for up to several million items. They are my favourite types of hash for use in typical business app logic.
For the last 20 years I would use some public CRC64 code stolen from the internet, but around November 2021 the NuGet package System.IO.Hashing was published with classes for the 32‑bit and 64‑bit versions of both the CRC and XxHash algorithms. Thank heavens! Now I can discard the borrowed code and use the provided classes.

|
For a more detailed discussion see blog post CRC vs Hash Algorithms |
32-Bit Hash
For reasons explained in Birthday Attack and Eric Lippert's article, 32‑bit hashes should not be used for more than a few hundred items. In such cases I originally used the FNV xor'd with a simple LCG (my own invention). In the rare cases that a persistent 32‑bit hash is needed I now use XxHash32. Avoid 32‑bit hashes if possible.
GetHashCode()
The current .NET string GetHashCode() method has acceptable behaviour for short strings, but improves quickly as the strings get longer. It's fast and convenient for internal code use. Don't use it like it's a real hash algorithm, don't persist the values and remember that in some .NET runtimes the hash values are only consistent for the lifetime of the AppDomain.
The Others
Everything else not mentioned so far should be ignored.
See also: Which hashing algorithm is best for uniqueness and speed?